Blockchain Data Stack: How Web3 Unleashes Proprietary Data for AI
According to Gate Research, in March 2025, investors poured approximately $247 million into blockchain infrastructure and data infrastructure projects alone. That influx signals a decisive shift: proprietary, permissioned data is now the most valuable feedstock for frontier AI models, and public-chain rails are finally mature enough to unlock it.
In the first part of this series, we introduced the five foundational layers of the Web3 data stack: acquisition, storage, indexing/querying, analytics, and marketplaces, as illustrated below. Through real-world examples such as ORO, Arweave, and Ocean Protocol, this paper examines three critical layers (Data Acquisition, Decentralised Storage, and Data Marketplaces / Compute‑to‑Data) to show how capture turns into commerce.
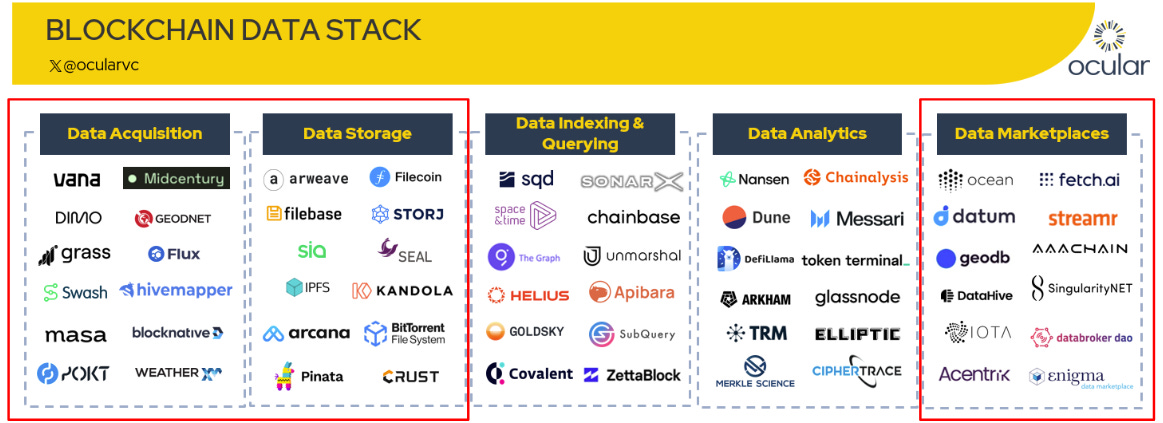
1. Data Acquisition
Data acquisition refers to the process of capturing raw information, which could include on-chain activity ( e.g. wallet transactions or smart contract interactions) and off-chain inputs ( e.g. browsing behavior, personal data, and IoT signals). In an AI-driven world, the availability, quality, and verifiable provenance of proprietary data directly affect model performance, regulatory compliance, and defensibility.
Web2 platforms like Google and Meta rely on centralized data collection models, where user information is gathered passively and often without clear, ongoing consent. Users have little visibility or control, and receive no compensation. Web3 flips the model in two transformative ways:
(1) By introducing token incentives that reward users for contributing valuable data, and
(2) By embedding privacy-preserving technologies that protect user control and confidentiality.
Together, these innovations enable a participatory data economy where users are active stakeholders.
1.1 ORO: Turn Your Data into Digital Gold
AI systems like ChatGPT and Stable Diffusion have relied heavily on large, diverse public datasets. But this open data supply is dwindling. A 2022 paper, Will We Run Out of Data?, predicts that high-quality public text could be depleted by 2026, with even low-quality content exhausted by the 2040s. This looming shortage raises a critical question: where will the next generation of AI models get their data?
ORO is a decentralized platform launched in 2025 that empowers individuals to contribute private data to AI development while maintaining full control and privacy. As public data sources dry up, ORO supplies high-quality, permissioned datasets for next-gen AI models. Users are fairly rewarded, turning personal data into a valuable asset. Advanced cryptography ensures privacy, building trust in the data economy.
Shortly after launch, ORO has attracted over 500,000 users and unlocked more than 1.5 million connections across health, social, and finance applications. It has also generated thousands of hours of high-quality, net-new audio data, already being licensed by frontier labs and application-layer companies - demonstrating early evidence of strong latent demand for a privacy-preserving data marketplace.
1.1.1 ORO’s Model
At the heart of ORO is a two-layered system: a data sharing application and a privacy-preserving blockchain protocol. Users connect their accounts and complete quests that collect specific data needed by AI companies. The more users participate (by linking accounts, completing quests, and maintaining engagement) the more points and eventual tokens they accumulate. All contributions and rewards are transparently tracked and distributed via smart contracts on the blockchain, ensuring fairness and eliminating the need for a central authority.
Crucially, raw files never leave the contributor’s device or the protocol’s secure enclaves, maintaining scarcity and thus economic value.
1.1.2 Data Quality Assessment in ORO
1. On-Chain Validation and Scoring
ORO employs on-chain validation and scoring mechanisms to transparently track and assess every data contribution. This system ensures that all data submissions are recorded immutably and can be audited for quality and provenance. The scoring process is designed to be trustless, meaning it does not rely on a central authority but instead uses protocol-defined rules to evaluate contributions.
2. Data Quests and Structured Contributions
Data is contributed through structured “quests” or account linkages, which are designed to collect specific, high-value data types needed by AI companies. By defining clear requirements for each quest, ORO can set minimum quality standards for the data being collected (e.g., completeness, recency, relevance to the quest objective). This structure helps filter out low-quality or irrelevant data at the point of submission.
3. Automated and Cryptographic Validation
ORO’s privacy-preserving technology, including zero-knowledge cryptography (zkTLS) and Trusted Execution Environments (TEEs), not only protects user privacy but also ensures that data is processed and validated securely. These technologies can verify that data meets certain integrity and authenticity criteria without exposing the raw data, helping to prevent fraudulent or manipulated submissions.
4. Ongoing Scoring and Reward Adjustment
The protocol’s reward system is directly tied to the quality and utility of the data provided. Contributors earn ORO Points based on the value their data brings to AI model improvement. If data is found to be incomplete, outdated, or otherwise low quality, it may receive fewer points or be excluded from reward calculations. This incentivizes users to provide accurate, timely, and relevant data.
5. Community and Protocol Oversight
While much of the validation is automated, ORO also supports the creation of Data DAOs, where communities can collectively curate, review, and govern data pools. This allows for additional human oversight and the ability to flag or remove low-quality data through community governance mechanisms.
1.1.3 ORO’s Privacy Protection Architecture
Privacy is foundational to ORO. It combines cryptography, secure hardware, and on-chain permissions to ensure contributor data stays safe and user-controlled.
1. Trusted Execution Environments (TEEs)
ORO utilizes Trusted Execution Environments to ensure that all user data is encrypted and processed within secure hardware enclaves. When data is contributed, it is never exposed to any human or external system; instead, all AI model training and data analysis are performed entirely inside these secure vaults. This approach guarantees that raw data remains private and inaccessible throughout its lifecycle on the platform.
2. Zero-Knowledge Cryptography and Multi-Party Computation
To further enhance privacy, ORO employs advanced zero-knowledge cryptography (zkTLS). This technology enables the platform to validate and process data without revealing the underlying information, preserving privacy during both storage and computation. Additionally, ORO supports Multi-Party Computation (MPC), which allows distributed data processing across multiple nodes without reconstructing the original dataset, adding another layer of security for sensitive information.
3. Encryption, Access Controls, and User Consent
All data on ORO is encrypted both at rest and in transit, using industry-standard protocols such as AES-256 and TLS. Access to data is managed through granular, on-chain permissions, providing precise control over who can access information and for what purpose. Contributors retain the ability to decide what to share, adjust permissions at any time, and revoke access whenever necessary, ensuring ongoing user consent and control.
4. Cryptographic Attestations and Transparency
Every operation involving user data on ORO generates a cryptographic attestation—a tamper-proof, auditable receipt that verifies data was handled as specified. These attestations are publicly accessible, offering transparency and verifiability for all data handling activities. Combined with a decentralized architecture and adherence to global privacy standards, this approach minimizes the risk of data breaches and establishes a foundation of trust for all participants.
1.2 Risks and Regulations
1.2.1 Regulatory Compliance
Compared to conventional data collection models (where data is often resold without user consent), decentralized data acquisition frameworks may offer a more compliant and user-centric alternative. Regulations like the EU Data Act emphasize data portability, transparency, and user ownership, principles that are inherently embedded in many Web3-native approaches. Similarly, U.S. laws such as the CCPA and HIPAA enforce strict consent and access controls, which can be more seamlessly implemented in decentralized systems through mechanisms like self-sovereign identity (SSI), verifiable credentials, and on-chain permissions. By design, these models minimize data custody risks and return agency to users, potentially making compliance not only easier but native to the architecture.
1.2.2 Risks
Synthetic Data Could Undermine the Value Proposition
A growing number of AI companies are exploring synthetic data generation to sidestep the limitations of real-world datasets. Startups like Parallel Domain and Synthesis AI use simulated environments and generative models to produce artificial datasets for applications ranging from autonomous vehicles to facial recognition.
However, multiple recent studies provide strong empirical evidence that synthetic data, even when carefully constructed, still underperforms compared to real data for large language model (LLM) training.
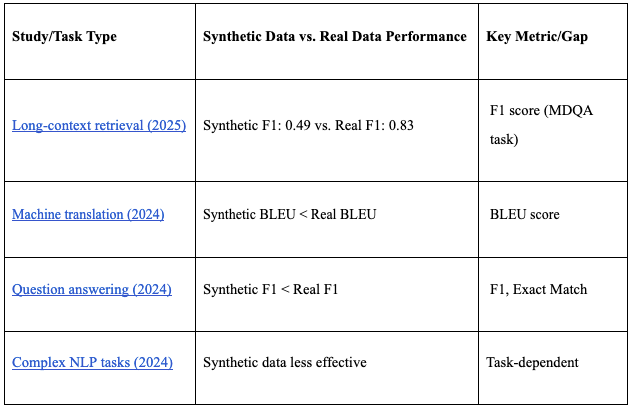
Source: Long-context retrieval (2025), Machine translation (2024), Question answering (2024), Complex NLP tasks (2024)
In areas like behavioural science, product design, or sentiment analysis, synthetic data falls short. Here, authentic human data remains irreplaceable, reinforcing the long-term value of permissioned user datasets.
1.3 Where Startups/Investors can Win in Data Acquisition
While the foundational tooling for decentralized data acquisition is maturing, there remain clear white spaces where new startups can deliver significant value. In particular, we see two underexplored areas: (1) the user experience layer for individual data contributors, and (2) B2B infrastructure to unlock enterprise-grade datasets.
1.3.1 UX Layer for Individual Data Contributors
Most current systems assume a level of technical literacy that excludes mainstream users. Concepts like wallet connections, trusted execution environments, or zero-knowledge proofs remain foreign to the average internet user. As a result, participation is limited to crypto-native individuals, constraining the available data supply.
This creates an opportunity for a new class of consumer-facing data tools that embrace chain abstraction to minimize friction. Data contribution should feel as effortless as linking a Spotify or Gmail account (no wallets, no tokens, no technical setup). Platforms should handle everything behind the scenes: wallet creation, chain selection, data formatting, and transaction execution. The user’s role should be reduced to a single, clear action: granting consent.
By abstracting complexity, platforms can onboard the next wave of data contributors - people who care about privacy and agency but don’t speak Web3.
1.3.2 Infrastructure for B2B Data Contribution
While most of the attention in Web3 data acquisition has focused on individuals, enterprises and SaaS platforms collectively hold vast repositories of valuable, structured data. However, there is currently no standardized way for these organizations to contribute datasets to Web3-native marketplaces while preserving compliance and control.
We believe there is a meaningful opportunity for middleware infrastructure that enables enterprises to tokenize, permission, and stream datasets into ecosystems like ORO. This could take the form of API-based integrations with existing enterprise software, allowing organizations to monetize anonymized or aggregated data in a compliant and opt-in manner. By tapping into the long tail of enterprise data sources, such infrastructure could dramatically expand the breadth and depth of supply available to data buyers, particularly those building AI, analytics, or personalization systems.
2. Data Storage: Why Decentralization Matters
Decentralised storage networks guarantee data permanence and censorship resistance, decoupling storage cost from centralized vendor pricing.
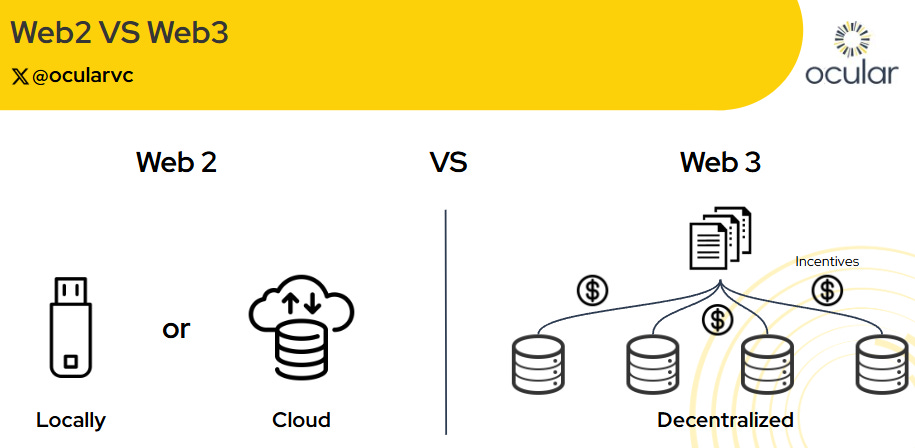
Traditional Storage vs Decentralized Storage
Web2 stores data either locally (hard drives) or in the cloud (AWS, Google Cloud). Local storage offers control but is fragile. Cloud storage adds durability but at the cost of control - miss a payment or lose access, and your data’s gone.
Decentralized storage reimagines this. Unlike early peer-to-peer systems like BitTorrent, Web3 adds incentives and on-chain verification. Protocols like Arweave, Filecoin, and Storj pay nodes to store and serve data, backed by cryptographic proofs.
Source: ocularvc
These solutions generally follow one of two models:
- Pay-once, store-forever (e.g. Arweave)
- Pay-as-you-use (e.g. Storj, Filecoin)
In this piece, we’ll focus on Arweave, the pioneer of permanent storage.
2.1 Arweave
Arweave is best described as a global hard drive, one designed to store data permanently. Unlike traditional cloud storage platforms that rent space month-by-month, users pay once using the $AR token to store the data forever,
2.1.1 Proof of Access: The Economic Engine Behind the Network
When you upload a file (say, a PDF) to Arweave, you pay a one-time fee in the $AR token. This fee is pooled and used to incentivize a decentralized network of miners to store that file over the long term.
But unlike traditional blockchains where every node must store the full history, or other storage networks where data is split into encrypted shards, Arweave takes a different approach:
- Data is stored directly in blocks.
- Each miner chooses which blocks to store, creating a diverse and redundant distribution of data across the network.
What ensures this system works is Arweave’s novel consensus mechanism: Proof of Access (PoA). To mine a new block and earn rewards, a miner must prove they have access to a randomly selected previous block (the recall block). This mechanism:
- Incentivizes miners to store rare or less-replicated data,
- Penalizes those who can't produce the required proof,
- And naturally balances storage load across the network.
This design turns scarcity into a feature. The rarer the data a miner stores, the higher their chances of earning rewards. This creates an economic engine that sustains long-term, decentralized storage without central coordination.
2.1.2 The Blockweave (A Smarter Blockchain Structure)
Instead of a typical blockchain, Arweave uses a blockweave, a structure where each block references not just the previous block but a random prior block (“recall block”). This enforces replication and decentralization without full-chain validation.
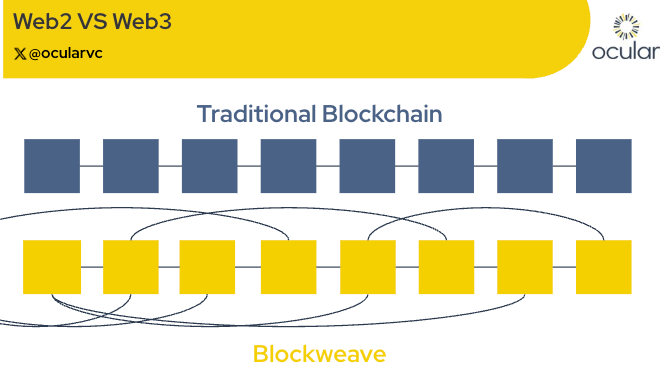
Source: ocularvc
2.2 Advantages and Risks
Decentralized storage spans multiple architectures, each with different trade-offs. While Arweave focuses on permanence, projects like Filecoin and Storj offer dynamic, cost-efficient, and privacy-preserving models. This section looks at the broader opportunities and risks across decentralized storage, not just Arweave.
2.2.1 Advantages
- Data Permanence as a Public Good
Today’s internet operates on fragile terms - websites can go offline, records may disappear, and historical context will be lost. Arweave changes that. Its economic model sustains permanent storage of critical public data like:
- Academic papers and scientific findings
- Legal documents, statutes, and governance records
- Historical media, journalism, and digital cultural artifacts
By aligning incentives for preservation, protocols like Arweave fill a gap that traditional cloud providers aren’t designed to address.
- Lower Cost Through Market-Based Storage (Filecoin & Storj)
On the other end of the spectrum, protocols like Filecoin and Storj operate on pay-as-you-go models. This model isn’t designed for permanence, but it does outperform traditional cloud pricing in many cases.
As shown in the cost comparison table below, Storj has a significant cost advantage. For users or businesses with large datasets and less concern about long-term immutability, decentralized storage is already an economically superior option. The combination of lower costs, open access, and redundancy makes decentralized storage a compelling infrastructure primitive for the modern data economy.
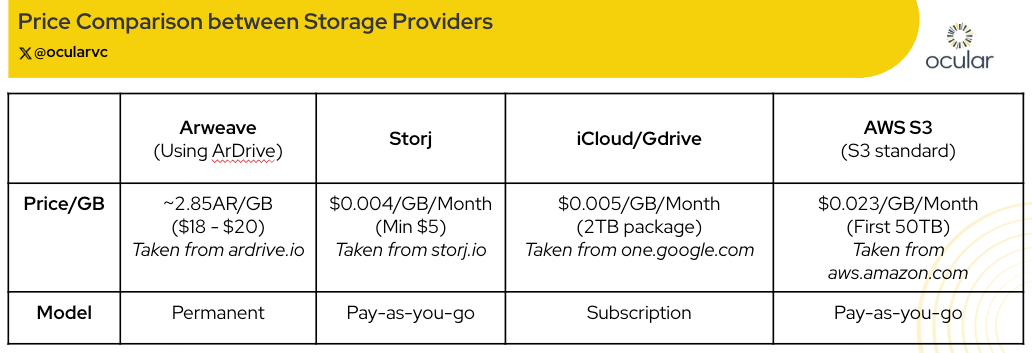
Source: ocularvc
2.2.2 Risks
- The Trilemma: Can’t Have Everything
Decentralized systems face trade-offs between permanence, privacy, and cost efficiency. No current solution delivers all three.
- Arweave offers unmatched permanence, but data is fully public unless encrypted by the user beforehand (through ArDrive). However, when using ArDrive, the cost becomes less competitive as seen in the table above.
- Filecoin and Storj prioritize privacy with very low costs, using sharding and erasure coding, but don’t offer guarantees of long-term persistence or immutability.
This reflects a broader Web3 trilemma: decentralization often comes with trade-offs that must be carefully considered depending on the use case.
- Miner Attrition and Infrastructure Fragility
Like other decentralized networks, storage protocols rely on active global node operators. But the same group of miners is being courted by multiple protocols. If incentives weaken through low demand or token price drops, miners may leave, reducing network reliability.
This makes the long-term sustainability of each network tightly coupled to its economic model, user adoption, and developer engagement.
2.3 Where Startups/Investors can Win in Data Storage
While decentralized storage protocols like Arweave, Filecoin, and Storj have made great strides in availability, permanence, and cost-efficiency, they fall short in addressing a rapidly growing and distinct need: structured, AI-ready data pipelines.
We believe there’s an emerging need for a unified AI-native storage layer in Web3, one that abstracts away raw infrastructure and offers clean, modular APIs optimized for model builders.
Such a platform would:
- Build on top of existing protocols like Filecoin or Arweave
- Add indexing, versioning, and retrieval pipelines
- Support privacy-preserving permissions (e.g. via ZK proofs or DIDs)
- Provide vector-native lookup for inference-time embeddings
- Enable tokenized incentive systems for structured, high-quality contributions
This verticalized “data operating layer” could become foundational infrastructure for decentralized AI. In our view, AI-ready storage represents one of the most overlooked primitives in the current Web3 infra stack, a critical missing link between decentralized data availability and real-world model utility.
3. Data Marketplaces
Web2 data marketplaces like Snowflake, AWS Data Exchange, Databricks, and Oracle Marketplace serve as centralized hubs where enterprises list structured datasets (typically for B2B use cases) behind paywalls or APIs. These platforms offer access to business intelligence, demographic, financial, and scientific records.
But access is tightly controlled. The most valuable data (Google search logs, Meta user behavior, Amazon purchases) stays behind corporate firewalls. Even third-party vendors like FactSet or Acxiom operate on pricey subscriptions, leaving smaller players out of the loop.
Web3 reimagines this model by shifting data ownership from institutions to individuals. Instead of relying on centralized brokers, users can directly contribute and monetize their personal data through decentralized, privacy-preserving marketplaces. These platforms typically feature:
- Privacy-preserving access via zero-knowledge proofs or compute-to-data,
- Tokenized incentives to reward contributors and curators,
- Smart contract-based licensing and settlement,
- Decentralized governance that gives contributors a voice.
While the space is still nascent, with only a handful of established players, we now turn to one of its most developed examples: Ocean Protocol.
3.1 Ocean Protocol:
Ocean is a decentralized data exchange protocol that turns datasets into tradable, tokenized assets. Through Data NFTs and Datatokens, Ocean enables programmable, privacy-preserving data sharing for individuals and enterprises. In mid-2024, Ocean merged with Fetch.ai and SingularityNET under the Artificial Superintelligence (ASI) Alliance.
3.1.1 Data NFTs & Datatokens
Ocean uses two main primitives:
- Data NFTs (ERC721): Represent IP ownership of datasets
- Datatokens (ERC20): Grant access rights to datasets, each tied to specific licensing terms.
A single Data NFT can have multiple datatokens, one for 24-hour access and another for full-month usage. This gives data publishers fine-grained control over pricing and distribution. Licensing and payments are handled entirely through smart contracts.
3.1.2 Smart Contract Flow
To publish data, creators deploy a Data NFT, then mint one or more Datatokens linked to it. Each token can use different pricing models (fixed rate, free access, etc.). This setup makes data assets tradable via Ocean Market or DeFi platforms.
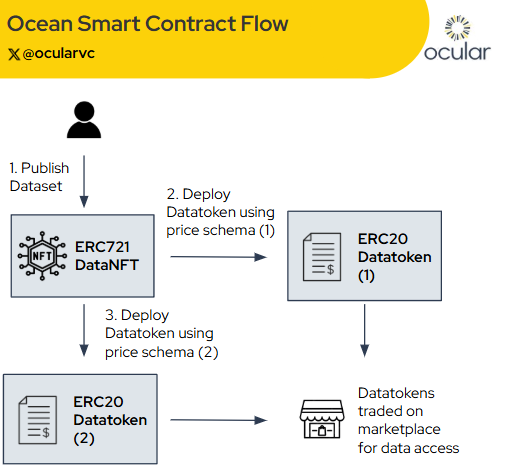
(A flowchart detailing the process of publishing dataset to datatoken being traded on marketplace), taken from Ocean Protocol docs
3.1.3 Compute-to-Data: Privacy-Preserving Access
One of Ocean Protocol’s most compelling innovations is Compute-to-Data (C2D), a privacy-preserving solution that enables data owners to monetize sensitive datasets without ever exposing the raw data. Instead of selling access to the data itself, owners can grant permission for specific algorithms to be executed on their dataset. Only the results of the computation are returned to the requester, while the data remains securely on-premise.
For example, a hospital might allow an algorithm to compute average patient age without revealing individual records. This privacy-preserving approach is ideal for sectors like healthcare, finance, or research where control and compliance are non-negotiable.
By separating compute from access, C2D unlocks value from sensitive data without compromising security.
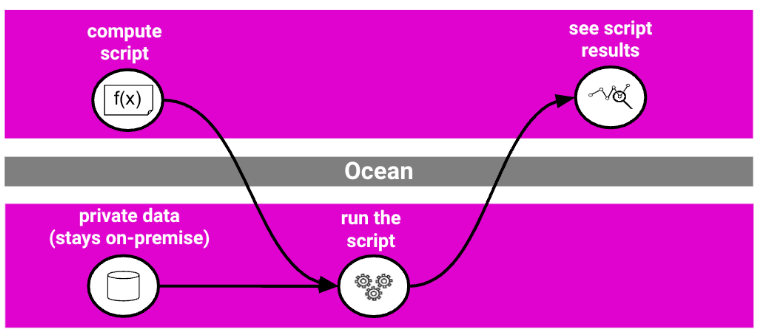
Source: Ocean Protocol Docs
3.2 Advantages and Risks
3.2.1 Advantages
- Discovery and Optionality
One of the core values of a marketplace is discovery. In today’s world, data demand often exists without clarity. Users may not even know what data they want until they see what’s available. A decentralized data marketplace surfaces new datasets, niche categories, and underutilized information. This enables a kind of “data browsing” experience and opens up novel use cases while encouraging experimentation. Much like eBay or OpenSea, users don’t always come in with a specific goal, sometimes the product finds the user.
- Monetization and Distribution Infrastructure
Marketplaces unlock new distribution and monetization models that don’t exist in Web2. Through primitives like Datatokens, Data NFTs, and Compute-to-Data, data can be monetized not just as a static file, but as a programmable, access-controlled asset. Sellers can choose to:
- Sell access rights without giving up data ownership (via Datatokens),
- Sell the revenue stream (via the NFT),
- Or even allow usage-based monetization via smart contracts. (Different price schemas)
This flexibility enables businesses, researchers, and even individuals to treat data like an income-generating asset, severely expanding who can participate in the data economy and how.
3.2.2 Risks
Disintermediation and Quality Concerns
The marketplace model works best when there's a large, diverse pool of buyers and sellers. However, if the biggest, most resource-rich buyers go straight to the source, marketplaces may be left servicing only the long tail of the data economy.
We believe the white space lies in vertically integrated platforms that own both ends: acquisition and distribution. These platforms don't just list datasets, they own the entire pipeline: from consent-based data acquisition and validation, to licensing and monetization.
A strong marketplace must start by owning the supply side. Ultimately, data is gold and the marketplaces that succeed will be those that own the upstream gold mine, not just the storefront.
By treating data acquisition and marketplace distribution as a unified problem rather than two siloed layers, future platforms can build stronger network effects and deeper moats.
Conclusion
As the foundations of the decentralized data economy solidify, a new design space is emerging for how data is gathered, governed, and monetized. This shift is not just technical but philosophical, redefining trust, ownership, and value at the data layer.
At Ocular, we’re deeply excited about the potential of this space. We believe that the protocols being built today will serve as foundational infrastructure for tomorrow’s innovations.
Thoughts and takeaways:
- Decentralized data acquisition, storage, and marketplaces are rapidly maturing, with clear opportunities for new entrants in privacy, compliance, and programmable monetization.
- Key risks include synthetic data competition, incentive sustainability, and the Web3 trilemma → no single solution offers permanence, privacy, and cost efficiency.
- Protocols with robust privacy-preserving primitives and high-quality data curation are best positioned to capture value as the data economy evolves.
In the next installment of this series, we’ll dive into how data is accessed, queried, and transformed into insights. We will explore indexing protocols, analytics platforms, and emerging data rails powering the next generation of permissionless intelligence.
Stay tuned.

.png)
.png)
